Introduction
Alice Retrieval-Augmented Generation (RAG) is a proof-of-concept application designed to address queries about the classic novel Alice’s Adventures in Wonderland by Lewis Carroll. By harnessing the power of modern AI, this proof-of-concept seamlessly integrates retrieval-based and generation-based approaches. It employs a language model coupled with a knowledge store, enabling precise and fast retrieval of information from the book, subsequently generating responses related to Alice’s Adventures in Wonderland.
This project demonstrates my expertise in implementing advanced AI techniques, containerization, CI/CD, documentation, infrastructure as code (IoC), and web-based interaction through Streamlit, adhering to best practices in software development and deployment.
Project Overview
This section provides a comprehensive overview of the application, its components, and the technologies used to build Alice RAG. Detailed descriptions of the system’s architecture, user interaction, and the AI model are provided in subsequent sections.
User Interaction
The interface, built using Streamlit, is designed to be user-friendly, intuitive, and efficient for interacting with the Retrieval-Augmented Generation system. Key components include:
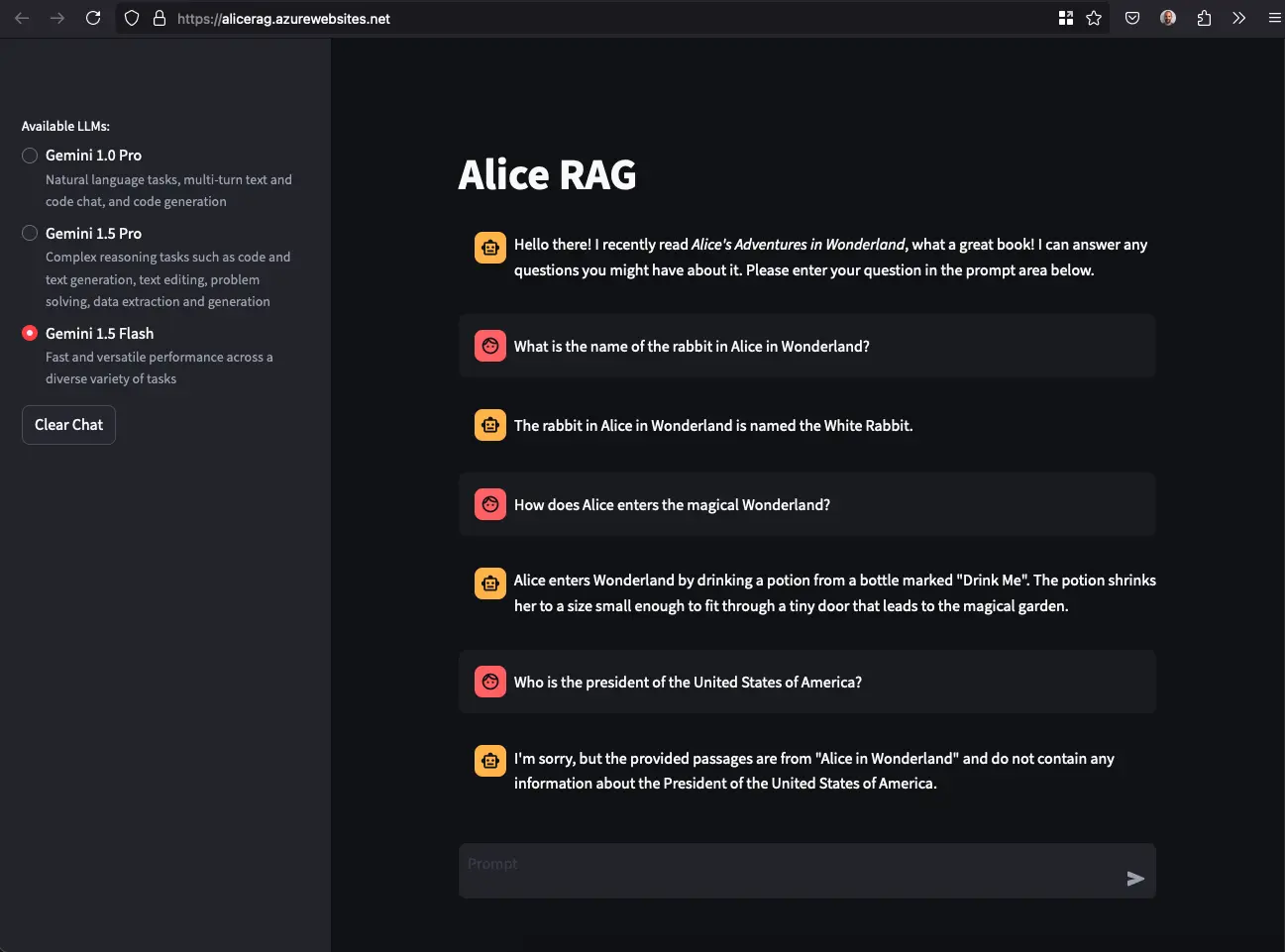
- Chat Window: The main area for conversation, displaying user inputs and AI responses in a chat-like format. Responses are streamed in real-time for better feedback and interaction. Icons differentiate between user queries and AI responses.
- Sidebar: Allows the user to select the model for querying the document, optimizing system performance.
- Input Field: A text box where users can type their questions, known as prompts.
- Send Button: Submits the text entered in the input field, either by clicking or pressing Enter on the keyboard.
Document Retrieval (Vector Database)
Alice RAG utilizes LlamaIndex for ingesting documents and creating a vector store. The embedding model used is BAAI/bge-small-en-v1.5. To keep the repository lightweight, datasets and embeddings are fetched and generated during the Docker image build process.
The following command downloads the document from the Gutenberg Project and stores it in src/documents/. It also creates and stores the embeddings in src/store/.
python src/store.py
The store.py module contains two classes: Book and VectorStore, used to load the document and interact with the vector database. The Book class represents the document data, while the VectorStore class creates the vector store, saves or loads the embeddings, and retrieves the most relevant passages for a query.
When a user provides a query, it is appended as follows:
f"Represent this sentence for searching relevant passages: {query}"
before retrieving top passages from the vector database, as recommended in BAAI’s documentation.
Prompt Generation
Top passages retrieved from the vector database are then combined with the user’s query to generate a prompt for the selected Gemini model. The prompt follows guidelines from the Gemini documentation and a detailed article on RAG architecture. The format is as follows:
def make_rag_prompt(query: str, passages: list[str]) -> str:
escaped_passages = "\n\n".join(passage.replace("\r", " ").replace("\n", " ") for passage in passages)
prompt = (
"You are a helpful and informative bot that answers questions using text from "
"the reference passages included below. Be sure to respond in a complete sentence, "
"being comprehensive, including all relevant background information. However, you "
"are talking to a non-technical audience, so be sure to break down complicated "
"concepts and strike a friendly and conversational tone. If the passages are "
"irrelevant to the answer, you may ignore them.\n\n"
f"QUESTION: {query}\n\n"
f"PASSAGES: {escaped_passages}\n\n"
"ANSWER:\n"
)
return prompt
Large Language Model
Alice RAG allows users to choose from three Gemini models.
- Gemini 1.0 Pro
- Gemini 1.5 Pro
- Gemini 1.5 Flash
Gemini models were selected due to Google offering a limited free tier API.
The first model, Gemini 1.0 Pro which is from the previous generation, provides simpler and less accurate answers compared to the newer Gemini 1.5 models. The two latest models offer higher accuracy but are generally more expensive and slightly slower. The default model is set to Gemini 1.5 Flash, which provides fast and versatile performance across diverse tasks. Users can change the model via the left sidebar to optimize their experience.
How to use it?
Building the Container
Follow these steps to build the container for Alice RAG. The Dockerfile in the repository is configured to set up all the required dependencies.
git clone git@github.com:philippemiron/alice-rag-llm.git
cd alice-rag-llm/
docker build -t alice-rag-llm .
This will create a container image named alice-rag-llm in your local Docker registry (can be viewed with docker images).
Running Locally
To run the container locally and interact with Alice RAG:
- Ensure you have a valid Gemini API token (Google AI Developers).
- Use the following command to run the Docker container locally, exposing the application on port 8501, and setting the
GEMINI_API_TOKENenvironment variable.
docker run -p 8501:8501 -e GEMINI_API_TOKEN="SECRET_TOKEN" alice-rag-llm
The application will then be accessible locally at http://0.0.0.0:8501.
Running directly from DockerHub
The container is also available on DockerHub (for amd64 and arm64) at pmiron/alice-rag-llm. You can pull the image from the repository and run it directly on your local machine.
docker run -p 8501:8501 -e GEMINI_API_TOKEN="SECRET_TOKEN" pmiron/alice-rag-llm:latest
Infrastructure as Code (IaC)
The bicep/ folder contains the Infrastructure as Code (IaC) scripts needed to deploy Alice RAG as an App Service in Azure. Below are the initial requirements and steps to set up the application.
Obtain an Azure account. New accounts receive a $200 credit and access to the free tier.
- Install the Azure Command-line Interface (CLI) using
brewon macOS or your favorite Linux package manager.
brew install az
Log in to your Azure account using the Azure CLI.
az login
Create a Resource Group where the resources will be deployed.
az group create --location eastus --name demo-app
Create the container registry by executing the Bicep template from bicep/infra/.
az deployment group create --resource-group demo-app --template-file bicep/infra/main.bicep --parameters containerRegistryName=aliceragllm
Log in to Azure Container Registry (ACR) to push the Docker image.
az acr login -n aliceragllm
Build the image (or pull the latest amd64 from DockerHub) and push it to ACR.
docker pull --platform linux/amd64 pmiron/alice-rag-llm:latest
docker tag pmiron/alice-rag-llm:latest aliceragllm.azurecr.io/alice-rag-llm:latest
docker push aliceragllm.azurecr.io/alice-rag-llm:latest
Deploy the application by executing the Bicep template from bicep/app/.
az deployment group create --resource-group demo-app --template-file bicep/app/main.bicep --parameters appServiceName=alicerag containerRegistryName=aliceragllm dockerImageNameTag=alice-rag-llm:latest geminiAPI=$GEMINI_API_KEY